- 社交媒体数据的价值
- 学术研究方向
- 社交网络分析:研究社交媒体上的网络结构,如分析Twitter上的转发链或Facebook上的朋友网络。
- 公众情绪分析:通过社交媒体上的文本数据分析公众对特定事件或话题的情感和情绪,如分析公众对政府政策的反应。
- 信息传播研究:探讨信息如何在社交媒体上传播,例如分析“冰桶挑战”等病毒式活动是如何在社交媒体上迅速传播的。
- 社交媒体上的健康传播:研究社交媒体在健康信息传播和健康管理中的作用,例如研究社交媒体上疾病预防的讨论。
- 商业应用领域
- 市场分析:分析社交媒体上的数据来了解消费者对特定产品或品牌的态度和偏好,以制定更有效的市场策略。
- 客户服务:使用社交媒体作为一个渠道来解决客户的问题和投诉,提高客户满意度。
- 目标广告:利用社交媒体用户的个人信息和行为数据,为特定的受众群体定制广告。
- 产品开发:通过社交媒体收集用户反馈和建议,改进现有产品或开发新产品。
- 投资和避险:例如通过持续实时监控对特定行业和金融产品能够产生重大影响的特定关键人物或区域相关的信息,及时进行相关操作。
- 政治和公共政策
- 选举和竞选:分析社交媒体上的公众舆论,制定竞选策略,监测竞选活动的影响。
- 社会动员:通过社交媒体发起和组织抗议活动或其他社会运动。
- 政策制定:收集社交媒体数据以理解公众对政府政策的看法和反应,用于支持政策制定和评估。
- 公共安全和健康
- 危机管理和应急响应:通过分析社交媒体数据快速检测自然灾害或其他危机事件,并有效部署救援资源。
- 犯罪预防和侦查:使用社交媒体数据来监控和分析可能的非法活动或威胁。
- 疾病监测和管理:通过分析社交媒体上的讨论和发布来监测潜在的疾病暴发或了解患者对治疗的反应。
- 心理健康:分析社交媒体数据来识别可能面临心理健康问题的个人,并提供支持和干预。
- 教育和人文
- 在线学习:使用社交媒体工具和数据来增强在线教育,提供交互式学习体验。
- 教育趋势和需求分析:分析社交媒体上的讨论来了解教育领域的热点话题和学习需求。
- 文化研究:分析社交媒体上的内容和讨论,以理解不同文化和社区的特点和价值观。
- 学术研究方向
- 当前基于社交媒体数据的热门研究方向:
- 计算机科学
- 自然语言处理:利用社交媒体数据进行情感分析、文本分类、话题建模、以及假新闻检测等。
- 机器学习:开发和应用算法来分析社交媒体数据,如用户行为预测、推荐系统等。
- 网络科学:研究社交网络的结构和动态,包括社区发现、信息传播、网络影响分析等。
- 社会科学
- 传播学:研究信息在社交媒体上的传播方式,例如信息扩散模式、传播网络分析。
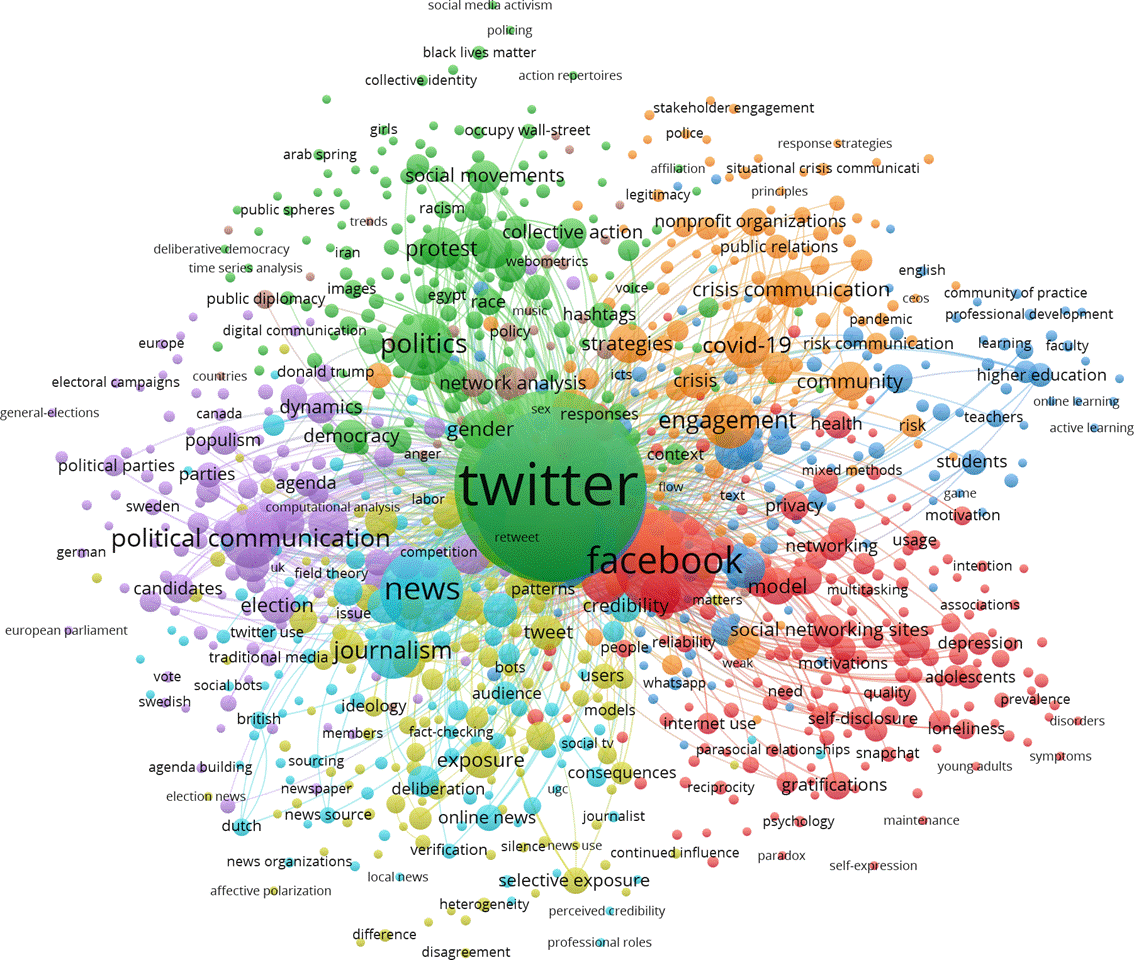
- 使用Web of Science在线数据库,以SCIE和SSCI为检索范围,搜索以Twitter为主题的学术论文,截至2022.12.05,共有16614项返回结果,均发表于Twitter问世的2006年至今。其中中观主题(Topics Meso)为Communication的有3669篇,用VOSviewer对这3669篇论文进行All keywords的Co-occurrence分析,限制为只统计共现5次以上的关系。生成的关键词共现网络如上图。图中节点的大小代表词频,连线代表共现存在共现,并用不同颜色标识出7个显著的Clusters和1个较不明显的由其他小型Clusters合并得来的Cluster,其所代表的研究热点大体可以描述为:
- 绿色:抗议运动:民主(阿拉伯之春)、性别、女权、种族、占领华尔街等
- 紫色:政治传播:选举、竞选活动、民粹、宣传等
- 青色:新闻业转型:新闻、新闻业、电视、受众、数字新闻、算法、事实核查等
- 黄色:公共空间及其败坏:极化、假新闻、错误讯息、谣言、情绪、选择性暴露等
- 红色:产业和效果研究:脸书、IG、社交网络、个性化、自恋、满足、隐私等
- 蓝色:社交媒体的积极效用:大数据、教育、技术、感知、游戏等
- 橙色:疫情传播研究:Covid-19、危机、策略、NGO、传播、社区、参与等
- 棕色:其他较小的主题:网络分析、中国、公共外交、政策、审查、公共参与、治理等
- 可以看到各主题内部的关键词紧密度较高、彼此之间的区分度较高,明显体现出不同的研究取向。尤其是关于现实政治表达的组1,其与其他各组特别是与作为现实政治参与的组2之间可谓泾渭分明,这与组4和组3几乎重叠且与组2相互渗透的情况形成了鲜明对比。这至少意味着多数现有研究在描述Twitter在这两类现实政治活动中的作用和意义时,使用了显著不同的话语体系。组8反映出至少在传播学领域,对于Twitter存在的问题的深入探究和应对策略的研究明显偏少。
- 使用Web of Science在线数据库,以SCIE和SSCI为检索范围,搜索以Twitter为主题的学术论文,截至2022.12.05,共有16614项返回结果,均发表于Twitter问世的2006年至今。其中中观主题(Topics Meso)为Communication的有3669篇,用VOSviewer对这3669篇论文进行All keywords的Co-occurrence分析,限制为只统计共现5次以上的关系。生成的关键词共现网络如上图。图中节点的大小代表词频,连线代表共现存在共现,并用不同颜色标识出7个显著的Clusters和1个较不明显的由其他小型Clusters合并得来的Cluster,其所代表的研究热点大体可以描述为:
- 政治学:分析社交媒体在政治活动中的作用,如选举、抗议活动、政府间的互动。
- 心理学:研究社交媒体使用与个人心理健康、社交行为、认知过程的关系。
- 传播学:研究信息在社交媒体上的传播方式,例如信息扩散模式、传播网络分析。
- 经济学
- 市场营销:分析社交媒体数据以研究消费者行为,品牌知名度和市场趋势。
- 行为经济学:通过社交媒体数据分析用户决策和偏好。
- 健康和医学
- 公共健康:利用社交媒体数据监测和预测公共健康问题,如流行病暴发、药物滥用。
- 医疗信息学:分析患者在社交媒体上的讨论来了解疾病、治疗和患者经历。
- 环境科学
- 灾害响应和管理:通过分析社交媒体数据来监测和响应自然灾害,如地震、洪水、飓风。
- 跨学科/综合
- 城市研究:结合社交媒体数据和其他数据源(如交通、气候)分析城市问题,如交通拥堵、空气质量。
- 人类行为和社交动态:跨足社会科学、心理学和计算机科学,研究个体和群体在社交媒体上的行为和互动模式。
- 社交媒体挖掘:使用数据挖掘和机器学习方法从社交媒体数据中提取有价值的信息和知识。
- 计算机科学
- 社交媒体数据的总体特征
- 宏观特征
- 大规模:社交媒体产生的数据量巨大,例如,每分钟在Twitter上发送数十万条推文。
- 高维度:包括文本、图片、视频、位置信息、时间戳等多种类型的数据。
- 实时性:社交媒体数据通常是实时产生的,如Twitter和Facebook上的动态更新。
- 噪声多:由于用户在社交媒体上的输入不受限制,数据中往往含有大量的错误、重复或无关信息。
- 网络结构:在信息和用户两个层级上,都存在着由用户行为所构建的互动关系,进而形成复杂的网络。
- 虚假信息多:某种程度上,社交媒体平台已经成为计算宣传战的主力战场。
- 结构特征:社交媒体数据包含了丰富的信息,大体可以分为用户发布的信息和用户账号的信息,最大的特征就是其中部分字段会随着时间推移而持续变化:
- 用户发布的信息:
- 相对固定的字段
- 正文:用户发布的文本内容。
- 媒体:用户发布的图片、视频等。
- 发布时间:信息首次发布的时间戳。
- 位置信息:如果开启,可以包含用户发布信息时的地理位置。
- 标签/话题:与发布内容相关的标签或话题。
- 随时间变化的字段
- 阅读量:信息被查看的次数。
- 点赞数:信息收到的点赞数量。
- 转发数:信息被转发的次数。
- 评论数:信息收到的评论数量。
- 统计汇总后的新指标
- 互动信息:与该信息所互动的其它信息。
- 互动用户:与该信息互动的用户列表。
- 影响力:发布特定时段后由各度量值酌情综合计算所得。
- 相对固定的字段
- 用户账号的信息
- 相对固定的字段
- 用户昵称:用户的显示名称。
- 用户名:用户的唯一标识。
- 注册时间:用户账号创建的时间。
- 个人简介:用户对自己的描述。
- 头像:用户的个人头像。
- 验证状态:是否是认证用户。
- 随时间变化的字段
- 粉丝数:关注用户的人数。
- 关注数:用户关注的人数。
- 总发布数:用户发布的总信息数。
- 统计汇总后的新指标
- 用户活跃度:例如,用户在一段时间内的发布频率。
- 用户影响力:例如,用户所发布信息在一段事件后的各度量值的不同统计所得值及进一步综合计算结果。
- 相对固定的字段
- 用户发布的信息:
- 随时间变化的度量值的统计特征
- 长尾分布:例如,一个社交媒体平台上的信息的阅读量,可能有少数信息的阅读量非常高,而大多数信息的阅读量相对较低。这种分布呈现出“头部”和“长尾”的特点。
- 幂律分布:在社交网络中,不同用户的粉丝数和关注数,往往遵循幂律分布,即少数用户具有大量的粉丝,而大多数用户只有少量的粉丝。
- 时间序列的波动:例如,某个话题的讨论量可能会随时间呈现周期性波动,或者在某些事件发生时出现突然的峰值。
- 互动网络特征。互动网络可以帮助我们更好地理解信息传播、社交影响和社区结构等方面。下面是一些主要的互动关系:
- 用户-用户互动关系:
- 关注:一个用户关注另一个用户,表明他们对另一个用户的内容感兴趣。
- 粉丝:一个用户被另一个用户关注,后者是前者的粉丝。
- 朋友:在某些社交媒体平台上,如果两个用户互相关注,则他们被视为朋友。
- 私信/聊天:用户之间可以通过私密的消息进行一对一或群组交流。
- 提及:用户在发布的信息中提及另一个用户,通常通过“@用户名”的格式。
- 标签共现:用户在发布的信息中使用相同的标签或话题,表现出共同的兴趣或参与。
- 信息-信息互动关系:
- 转发/分享:一个用户将另一个用户发布的信息转发或分享给自己的粉丝或朋友。
- 评论/回复:对于发布的信息,其他用户可以发表评论或回复。
- 引用:一个用户在自己发布的信息中引用另一个用户发布的信息。
- 点赞/收藏:用户可以对发布的信息表达喜欢或者收藏以后查看。
- 用户-信息互动关系:
- 发布:用户发布信息,创建内容。
- 阅读:用户浏览和阅读其他用户发布的信息。
- 互动:包括用户对发布的信息进行点赞、评论、转发和分享。
- 典型的关系网络:基于以上的互动关系,我们可以构建和分析不同类型的互动网络,进而揭示社交媒体中的信息传播模式、社区结构、影响力分布等重要特征
- 社交网络:以用户为节点,关注、粉丝、朋友等关系为边。
- 信息传播网络:以信息为节点,转发、分享、引用等关系为边。
- 用户-信息双层网络:以用户和信息为节点,发布、阅读、互动等关系为边。
- 用户-用户互动关系:
- 宏观特征
- 用于特定分析的社交媒体数据集的特征:
- 本质上是快照(及其集合):抓取时刻与创建时刻
- 通常是在特定短时段内,针对原本不同时刻所发表的信息进行抓取
- 有必要的话,可能是针对不同时刻所发布的信息,在经过大致接近时长后的某时刻分别进行抓取再汇总
- 结构化与非结构化:
- 数据本身由于获取方式往往是高度结构化且规整的
- 但是每条数据中的大部分内容相关字段的值是非结构化的,如文本、图片和视频。
- 噪声和不完整性:
- 由于获取方式和原则的多样性,可能会存在“重复”的情况,例如单条信息在不同时刻的快照
- 数据集的内容相对平台整体必然是不完整的,对于理论上理想的和研究目的相关的数据同样如此
- 本质上是快照(及其集合):抓取时刻与创建时刻
- 结合实操进行各环节演示:
- 数据获取,参考:02.数据获取和处理常识
- 相对来说,Twitter自创立以来,由于其开放API的策略,一直是相对最受欢迎的平台
- 但这一局势在Musk入主后最近正被迅速改变,例如砍掉学术API、限制用户每天读取条数等。
- 数据处理和基本分析:
- 数据清洗:清除无关数据,处理缺失值,标准化数据格式。
- 描述性统计分析:
- 计算基本统计量,如平均值,中位数,标准差等。
- 为数值型变量创建直方图或箱线图以查看其分布。
- 创建时间序列图以观察随时间变化的趋势和模式。
- 高级统计分析与建模:
- 预测目的:回归分析,时间序列分析,机器学习等
- 分类或分组目的:聚类分析,决策树,神经网络等
- 自然语言处理:针对文本内容进一步分析,如主题提取、情感分类等
- 多模态处理:针对多媒体信息,如图片、视频等进行进一步分析
- 网络分析:针对信息和用户间的互动关系构建网络并进一步处理
- 基于特定场景的探索分析:具体案例待定。
- 基于新词发现的热点主题自动识别
- 效果评估:特定领域的指标体系构建
- 社交媒体大数据实时分析平台
- 数据获取,参考:02.数据获取和处理常识
- 常用资源:这里只是列出一些相对常见易上手的,难免挂一漏万,而且其有效性会随时因为平台的功能、技术和政策变动而变化。
- 商业平台:
- Brandwatch Crimson Hexagon:社交媒体分析平台,用于监测趋势、观点和情感。
- Meltwater:社交媒体监听和分析平台,用于追踪和分析社交媒体上的讨论和趋势。
- 商业软件:
- NVivo:定性数据分析软件,用于分析社交媒体上的文本数据,包括对话、讨论和意见。
- Tableau:Tableau是一款商业智能工具,可以用于可视化社交媒体数据分析。
- NodeXL Pro:Excel插件,用于可视化社交媒体网络数据。基础版本免费,Pro版有一定的数据采集功能。
- 免费服务:
- Botometer:在线服务,印第安纳大学开发的一组社交媒体分析工具中最知名的一个,用于检测Twitter账户是否为机器人。
- Netlytic:用于文本和社交网络分析的云服务,可以分析社交媒体数据,包括Twitter、Facebook和Instagram。
- 开源软件:
- Gephi:开源的网络分析和可视化软件,用于分析社交媒体上的网络结构和社区。
- 库/脚本:
- Tweepy、Twarc:一些用于获取Twitter数据的Python库。
- TAGS (Twitter Archiving Google Sheet):允许用户通过Google表格归档Twitter数据的脚本,用于收集和初步分析数据。
- Facepager:从YouTube,Twitter和其他网站上获取公共可用数据,基于API和爬虫。
- 商业平台:
- 延伸阅读:
- 粗看长尾,细辨幂律:跨世纪的无标度网络研究纷争史:对于无标度网络有兴趣可以从这篇入手
- 社会网络分析手册(上):社会学家眼中的网络分析发展史
Do Some Solid Work

Specter
不知老之将至
